Kazakh-Russian Sign Language recognition
Kazakh-Russian Sign Language recognition GitHub
Paper, results and discussions can be found here
This project presents Kazakh-Russian Sign Language recognition method that involves the usage of MediaPipe library as feature extractor and LSTM RNN as a classification model to convert local video or a video stream directly into a text end-to-end. Main purpose of this project is develop general framework for further integration into robotic systems for Human-Robot Interaction projects and research, as the system implemetented is very lightweight and works on embedded systems. This is the project implemented by Shyngyskhan Abilkassov, Asset Malik, and Madi Nurmanov.
MediaPipe feature extraction
MediaPipe is a very useful tool that was have used as an alternative for OpenPose library. It is capable of extracting feature points of person’s hands from a video, locating them and classifying the spatial orientation of each finger separately. Use of MediaPipe freed accelerated the work, since it provided a ready framework and training separate convolutional neural network was not required. It helped to focus directly on development of algorithm of recognizing the signs.
Feeding video from file
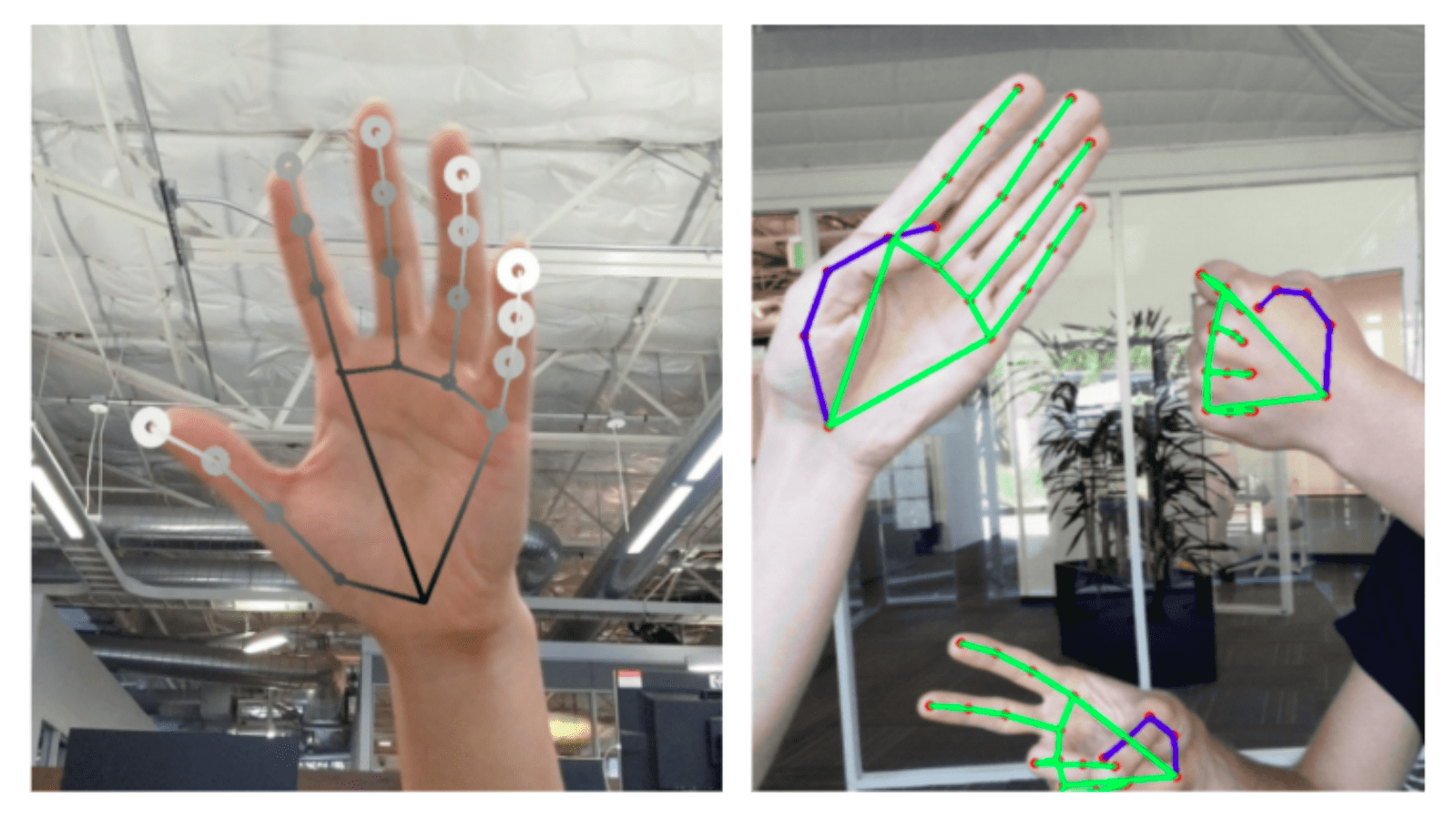
Initial MediaPipe graph demo architecture takes images taken from camera and draws landmark points directly on image. However, the training process requires data to be generated, classified, and shuffled in order to be fed into the training pipeline. This requires some updates to the internal MediaPipe structure. Therefore, updated internal calculators that output landmark data into txt files was used. The landmark data from video input was generated afterwards. The sample image with landmarks drawn by MediaPipe is represented in figure below.

Generated data
After running MediaPipe feature extraction on datasets, the list of folders containing txt files was generated. As it can be observed, each txt corresponds to a particular video and stores landmarks obtained from them. At each time instance, maximum number of 84 data points can be obtained, where 21 are number of landmark points as shown on figure below, each with a corresponding {x} and {y} coordinates, for two hands. Alongside the txt MediaPipe also generates video outputs that are exactly same in content as the input but with overlayed hand position marker and features for debugging and demonstration purposes. It is unknown whether disabling this action can increase the performance of the algorithm, but was ignored due to low priority of investigation. The output videos are also typically lower in weight, with almost 85% reduction in size for KRSL input.
RNN on LSTM cells
As the data used is a sequence of landmarks, the Recurrent Neural Network (RNN) model was used to train a recognition algorithm. Recurrent networks were first mentioned in the work of Rumelhart et al. and is the best suitable architecture as the sign language is a sequence of hand motions usually called glosses and the recognition algorithm must store and use the information in sequence. RNN is basically a network of cells that have a feedback loops and can store any information. However, the most prominent type of RNNs that proved its effectiveness are Long short-term memory (LSTM) models, which were initially introduced by Hochreiter and Schmidhuber and updated by multiple researchers worldwide. LSTMs are designed in such a way to overcome the main disadvantage of classical RNNs and are able to avoid the long-term dependency problem and therefore are able to store information for long periods of time. All RNNs are a chain of repeating modules of neural network with a simple structure like a single tanh activation function. However, LSTMs have a number of internal gates in single neural network layer which allows them to preserve information for long periods.
Architecture
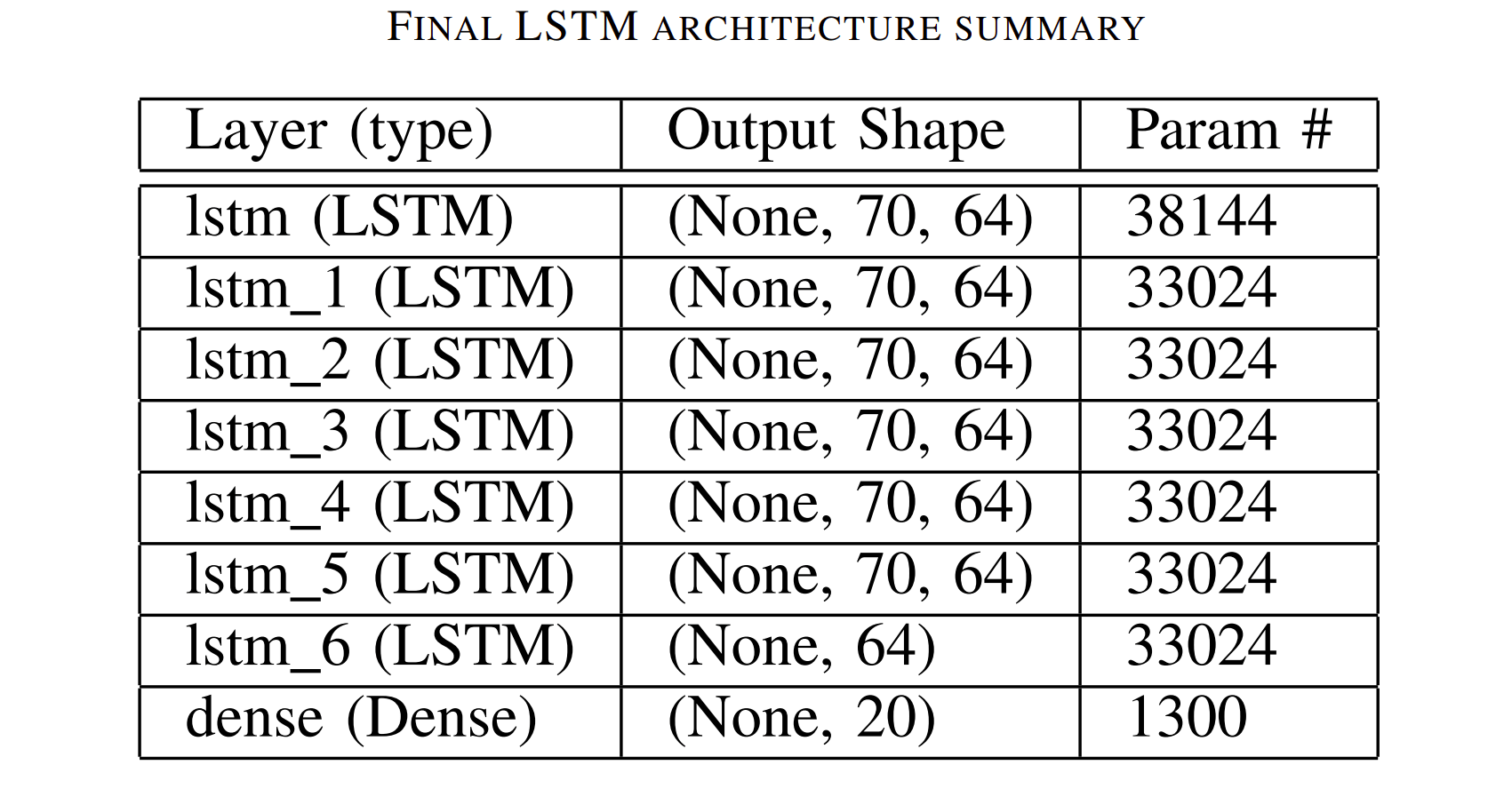
The final architecture consists of seven LSTM layers each consisting of 64 nodes. The first six have a return sequences mode turned on which allows to pass the network output of the full sequence of hidden states to the last layer. The model architecture summary is represented in Table below. Total trainable parameter number is 237,588.
Results
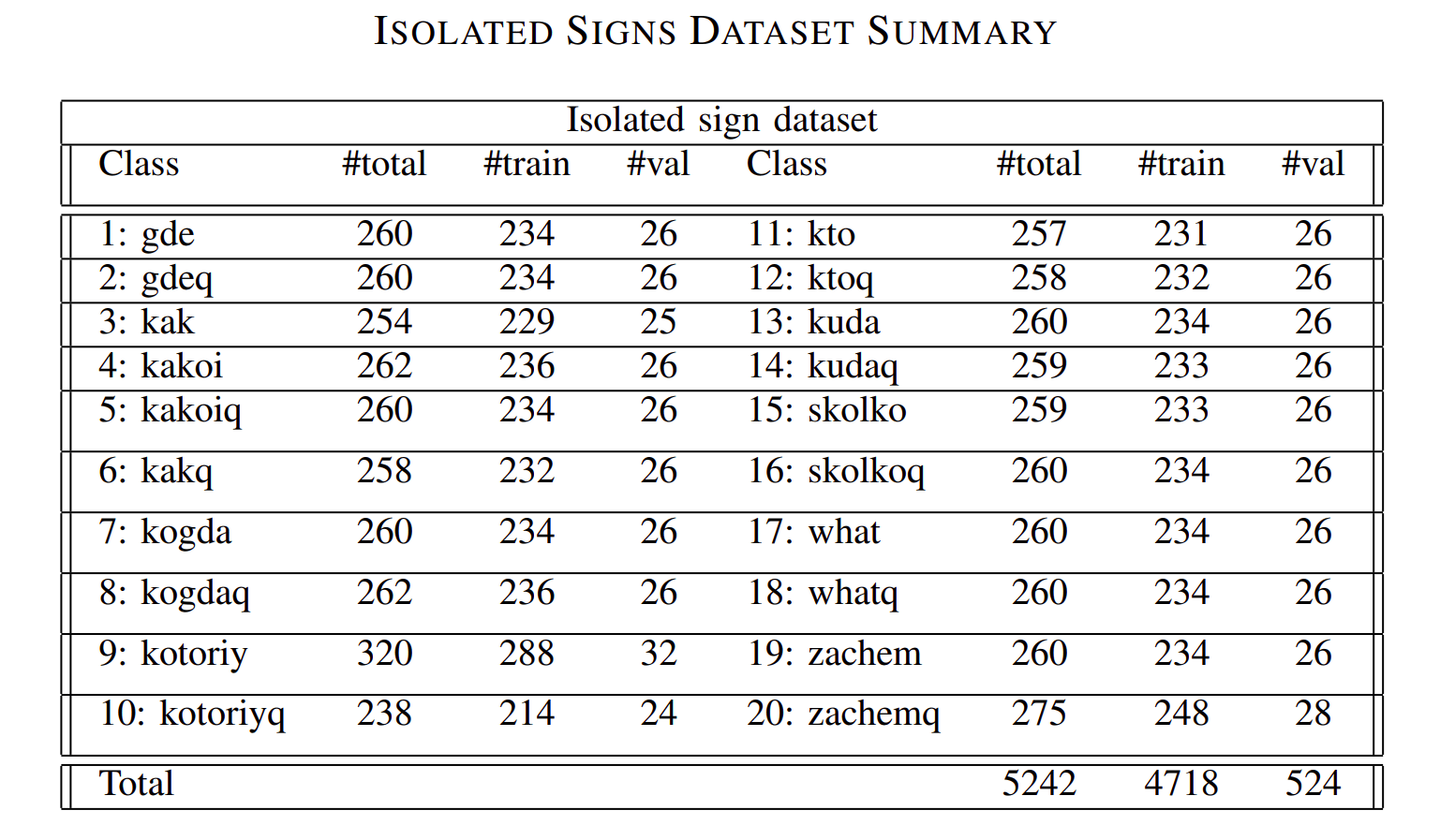
The training was made on Isolated Signs dataset which consists of 20 classes, each corresponding to a particular word. These words are shown in the table. Some of the words had a pair with words that have a question mark in the end. Therefore, some classes were of high similarity with only minor gloss difference. The input to the model is a vector consisting of 84 data points. Each hand has 21 landmarks, with point having x and y coordinates, made for two hands. As there were some videos where only one hand visible, the left data points were filled with zeros. The training data was split into two parts: training and validation. Validation data used was 10% of the whole data. The final training was made for 250 epochs which took only approximately 2 hours of GPU training on a laptop. The final accuracy achieved was 88.74%. Afterwards, training also was done using the short list data from the KRSL dataset shown in table below, and training accuracy peaked at around 70% accuracy with 100 of epoch for training. Nevertheless it has shown that the RNN can be trained on a more complex data as multiple words and collocations, but more data and time for training is required.
Discussion and Conclusion
The resulting system is a prototype of Kazakh-Russian Sign Language recognition pipeline. It uses a video as an input and produces text output as a result of several processing techniques application. Accuracy of the solution, which fluctuates around 88% is a good result. However it can cause some undesirable artifacts or create sources of miscommunication. Usage of larger datasets in combination with further tuning of the parameters of neural networks can contribute in the overall improvement of the system. Another essential application of larger dataset processing is expansion of the dictionary that the system operates and interprets. Currently, the short list is consisting only of 10 phrases, which is a small part of KRSL dataset. Including the total of 173 phrases from KRSL and combining them with other sources can influence the performance of the system and possible application.